app后台挂掉问题汇总
报错:
数据库连接池不可用

查询报错信息HikariPool-1 -Connection is not available, request timed out after ms.得到结果
连接池里的连接不够用了,因为在等待连接所以超时了 |
需要增加以下代码到项目后端配置文件中
#客户端等待连接池连接的最大毫秒数 |
CPU突然飙高

通过top查看CPU最高的进程

#客户端等待连接池连接的最大毫秒数 |
2.云服务器CPU飙升可能为上次版本代码中的有效时间问题,在6.08号版本生产上线中解决
3.项目不能访问后没有即刻告警,因为该服务没有停止运行,但是内部已经连接超时,无法响应。针对此情况新增监控告警,该告警为监控日志报错后告警,时间间隔为10分钟,通过手机短信,邮箱,钉钉机器人报警

进入到监控中查看CPU和内存均正常

查看nhospital容器对应的的CPU和内存,CPU达到80%但没超过限制值

内存在1.8G时进行重启容器(分配内存为2.2G)
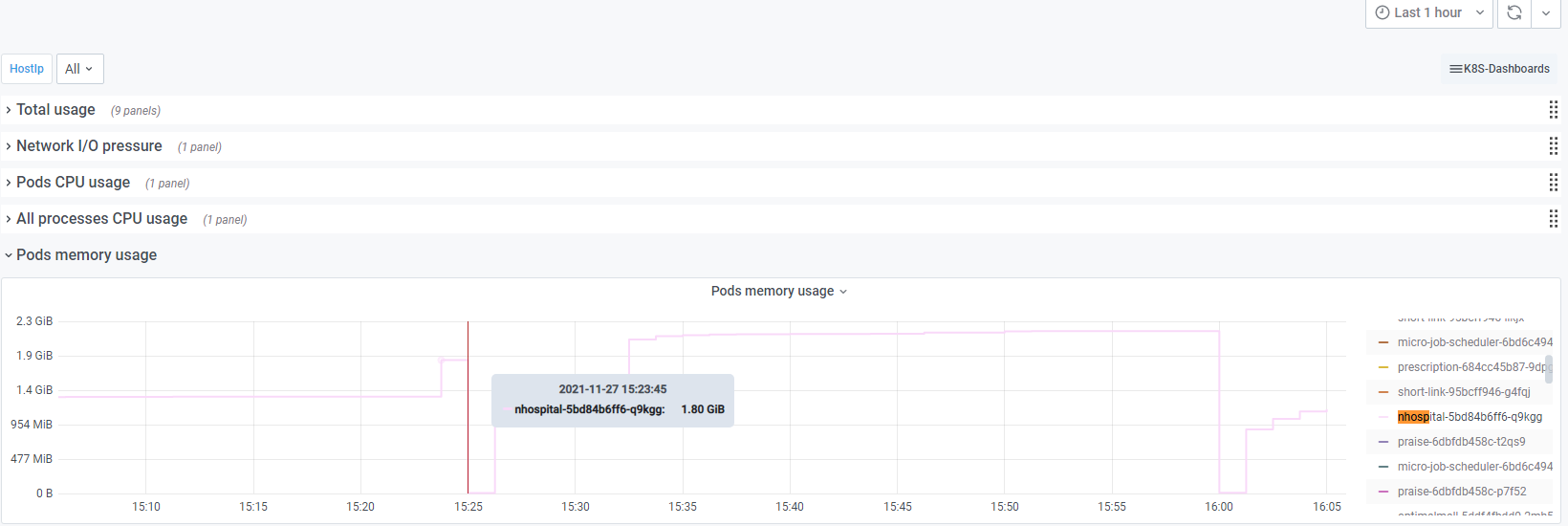
查看该节点对应的/var/log/message得知容器被OOM杀掉进程
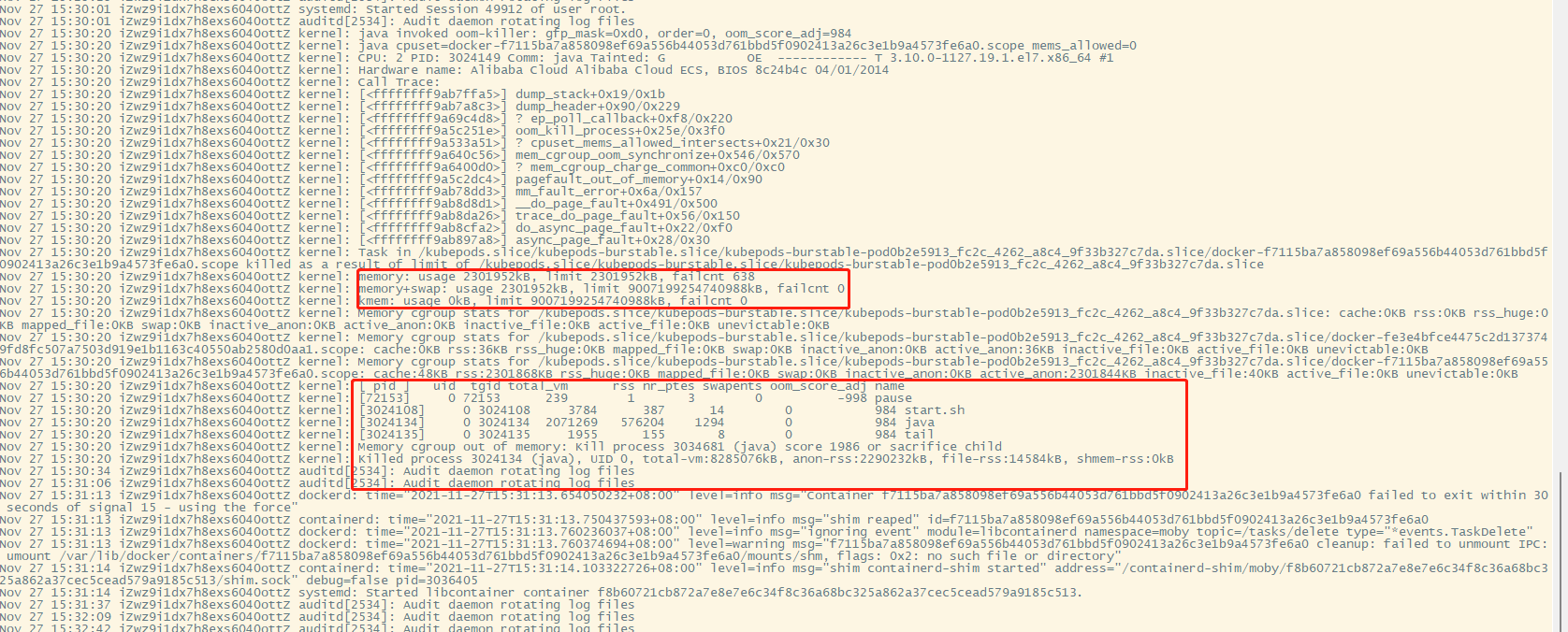
OOM:
如果节点在 kubelet 回收内存之前经历了系统 OOM(内存不足)事件,它将基于 oom-killer 做出响应。
kubelet 基于 pod 的 service 质量为每个容器设置一个 oom_score_adj 值。
| Service 质量 | oom_score_adj |
|---|---|
| Guaranteed | -998 |
| BestEffort | 1000 |
| Burstable | min(max(2, 1000 - (1000 * memoryRequestBytes) / machineMemoryCapacityBytes), 999) |
如果 kubelet 在节点经历系统 OOM 之前无法回收内存,oom_killer 将基于它在节点上 使用的内存百分比算出一个 oom_score,并加上 oom_score_adj 得到容器的有效 oom_score,然后结束得分最高的容器。
预期的行为应该是拥有最低服务质量并消耗和调度请求相关内存量最多的容器第一个被结束,以回收内存。
和 pod 驱逐不同,如果一个 Pod 的容器是被 OOM 结束的,基于其 RestartPolicy, 它可能会被 kubelet 重新启动
QoS类型:
Guranteed:
每个容器的CPU,RAM资源都设置了相同值的requests 和 limits属性。
简单说: cpu.limits = cpu.requests
memory.limits = memory.requests
这类Pod的运行优先级最高,但凡这样配置了cpu和内存的limits和requests,它会自动被归为此类。
Burstable:
每个容器至少定义了CPU,RAM的requests属性,这里说每个容器是指:一个Pod中可以运行多个容器。
那么这类容器就会被自动归为burstable,而此类就属于中等优先级。
BestEffort:
没有一个容器设置了requests 或 limits,则会归为此类,而此类别是最低优先级。
QoS类型的作用:
Node上会运行很多Pod,当运行一段时间后,发现Node上的资源紧张了,这时K8s就会根据QoS类别来选择Kill掉一部分Pod,那些会先被Kill掉?
当然就是优先级最低的,也就是BestEffort,若BestEffort被Kill完了,还是紧张,接下来就是Kill中等优先级的,即Burstable,依次类推。
这里有个问题,BestEffort因为没有设置requests和limits,可根据谁占用资源最多,就kill谁,但Burstable设置了requests和limits,它的kill标准是什么?
若按照谁占资源多kill谁,那遇到这样的问题,怎么选择?
PodA: 启动时设置了memory.request=512M , memory.limits=1G
PodB: 设置为: memory.requests=1G, memory.limits=2G
PodA: 运行了一段时间后,占用了500M了,它可能还有继续申请内存。
PodB: 它则占用了512M内存了,但它可能也还需要申请内存。
想想,现在Node资源紧张了,会先kill谁?
其实,会优先kill PodA , 为啥?
因为它启动时,说自己需要512M内存就够了,但你现在这么积极的申请内存,都快把你需求的内存吃完了,只能说明你太激进了,因此会先kill。
而PodB,启动时需要1G,但目前才用了1半,说明它比较温和,因此不会先kill它。
解决方案:
挂掉的nhospital容器的资源配置为:
cpu.request=0.1m cpu.limit=0.9m memory.request=512M memory.limits=2248M
故nhospital容器的Qos类型为Burstable,若该容器比较激进使用内存容易被kill
修改nhospital容器的资源配置为:
cpu.request=0.1m cpu.limit=0.9m memory.request=2248M memory.limits=2248M
当pod 内存超过limit时,会被oom。
当cpu超过limit时,不会被kill,但是会限制不超过limit值。
所以只修改memory的request跟limit保持一致即可
这样nhospital容器的Qos类型就变为了Guranteed,分值最低不会被kill
当前节点池中的节点内存使用量都在73-78%,当其他服务内存增长过高情况下会导致会先oom情况,可进行内存扩容进行避免OOM发生
代码获取不到客户端真实ip
排查一:
查看nginx服务器配置转发是否正确 |
排查二:
查看k8s中的ingress转发是否正确 |
修改proxy_set_header X-Forwarded-For $remote_addr;中的$remote_addr为 $proxy_add_x_forwarded_for;
再次进行获取客户端真实ip,获取正常
2021年9月18号出现宕机问题汇总
- 在10:43分左右出现app登录不上问题,查看项目报错日志
Exception in thread “Thread-38” org.springframework.jdbc.BadSqlGrammarException: Error selecting key or setting result to parameter object. Cause: org.postgresql.util.PSQLException: 错误: 语法错误 在 “PostgreSQL” 或附近的
Position: 1
; bad SQL grammar []; nested exception is org.postgresql.util.PSQLException: 错误: 语法错误 在 “PostgreSQL” 或附近的
Position: 1
是由上述报错导致项目挂掉,找到该接口负责人,进行修改.重新提交代码后,进行重新发布
再次观察监控得知再次宕机
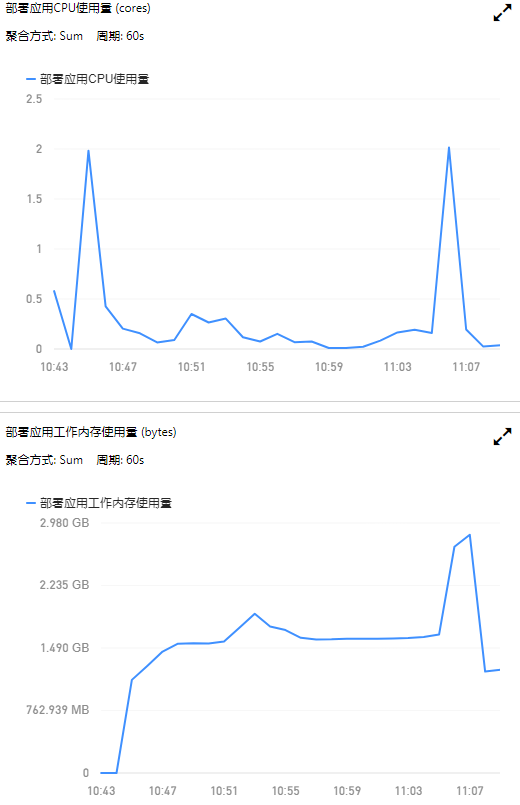
查看日志未有报错,CPU和内存溢出.又收到都市大医生也出现宕机问题,加大项目节点观察是否宕机还是出现问题
通过nginx查看请求的ip和URL 通过访问地址进行分析
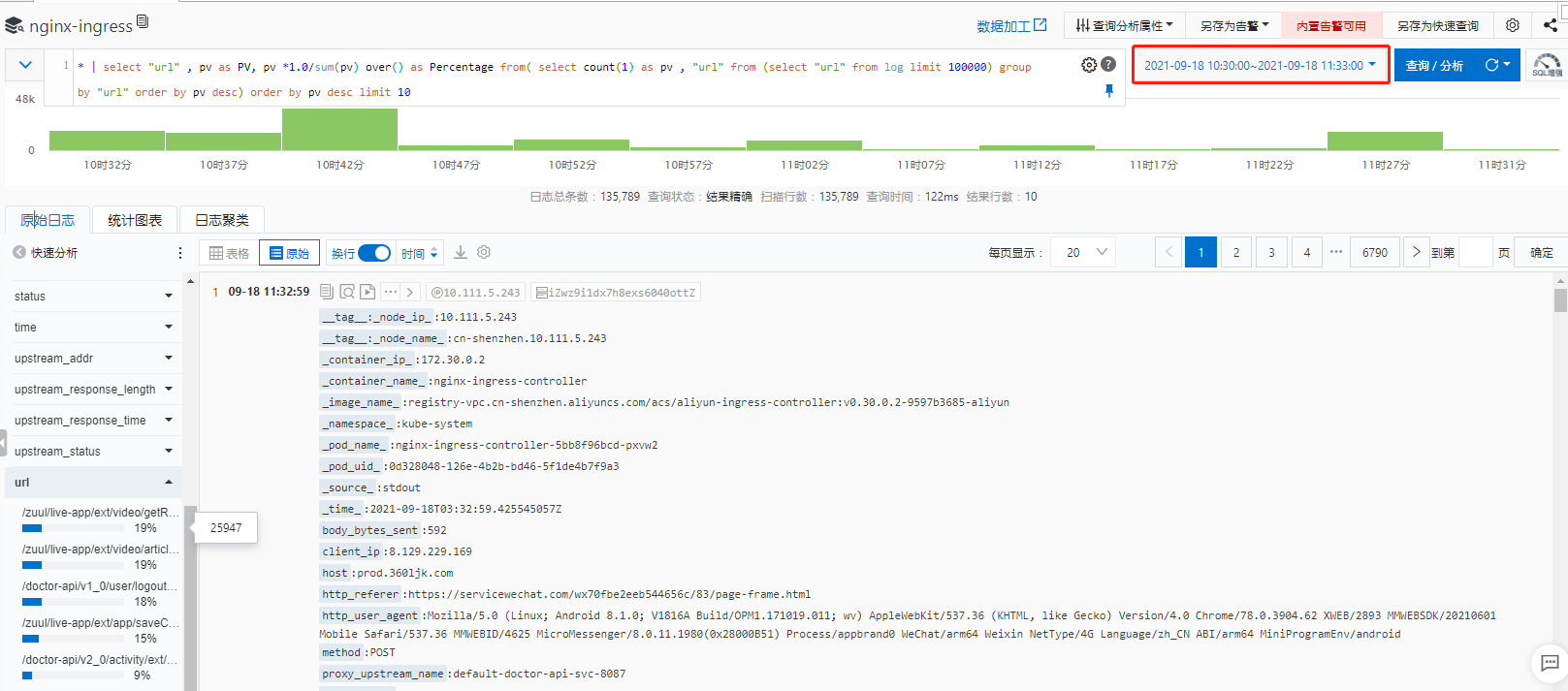
| 前4个请求最多的地址为: | 业务 |
|---|---|
| /zuul/live-app/ext/video/getRandomProduct | 首页推荐视频 |
| /zuul/live-app/ext/video/article/recommended | 首页推荐文章 |
| /doctor-api/v1_0/user/logoutForLj | 用户退出登录 |
| /zuul/live-app/ext/app/saveChannel | 上报渠道 |
查看得知用户退出登录接口的请求次数为25600次,上传渠道接口的请求次数为21474次
得出结论:
用户退出登录接口导致服务宕机,使用户无法访问都市大医生,上报渠道接口导致接口出现无法访问问题
协助开发查询代码问题,找到问题原因,用户退出登录接口一直在死循环请求服务器,导致服务一直重启.上报渠道接口因修改app登录不上时出现了502,也会一直请求服务器.开发进行重新修复代码问题后,重新打出app包.再无问题出现
后续
该问题为代码问题,都是正常的请求,但是出现了死循环,加大服务器节点和内存无法避免该情况发生,只能通过排查代码中的问题来解决.