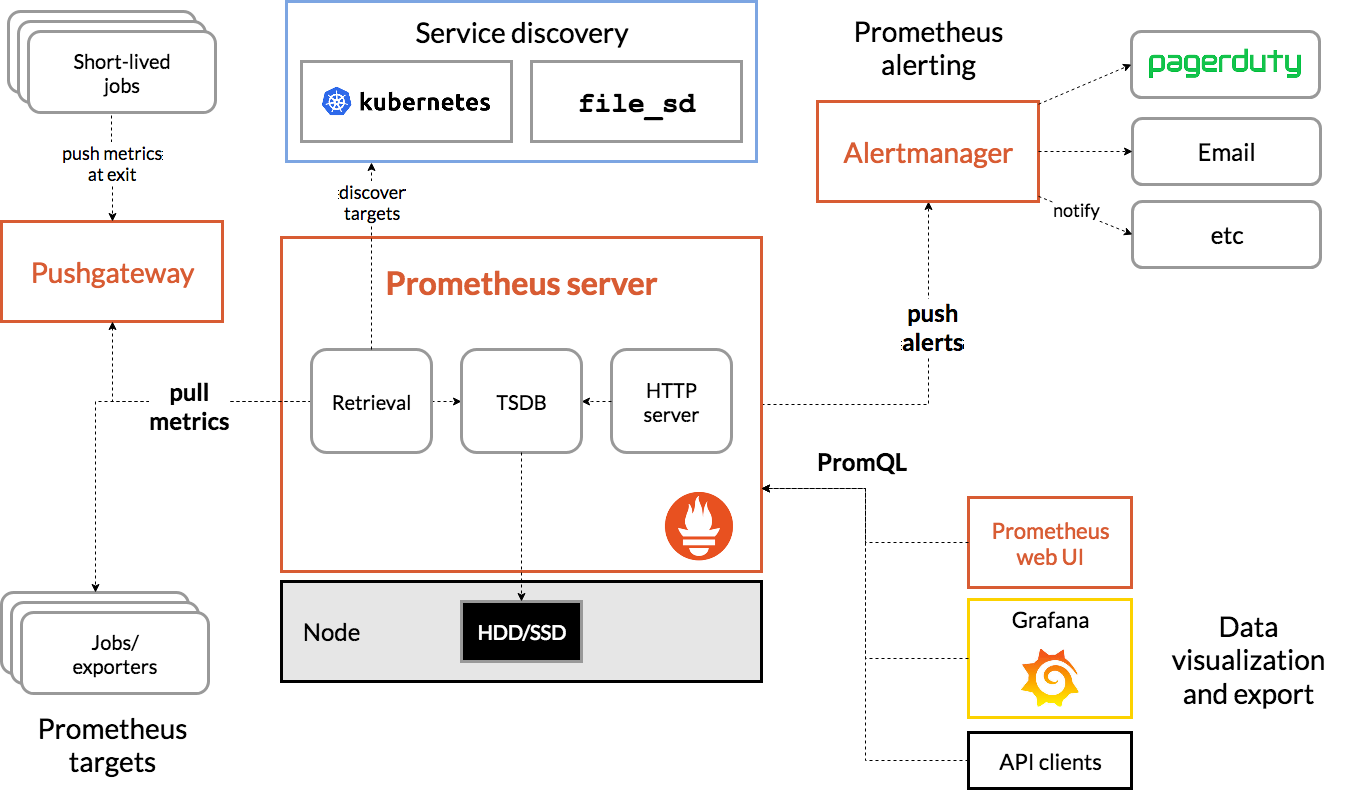
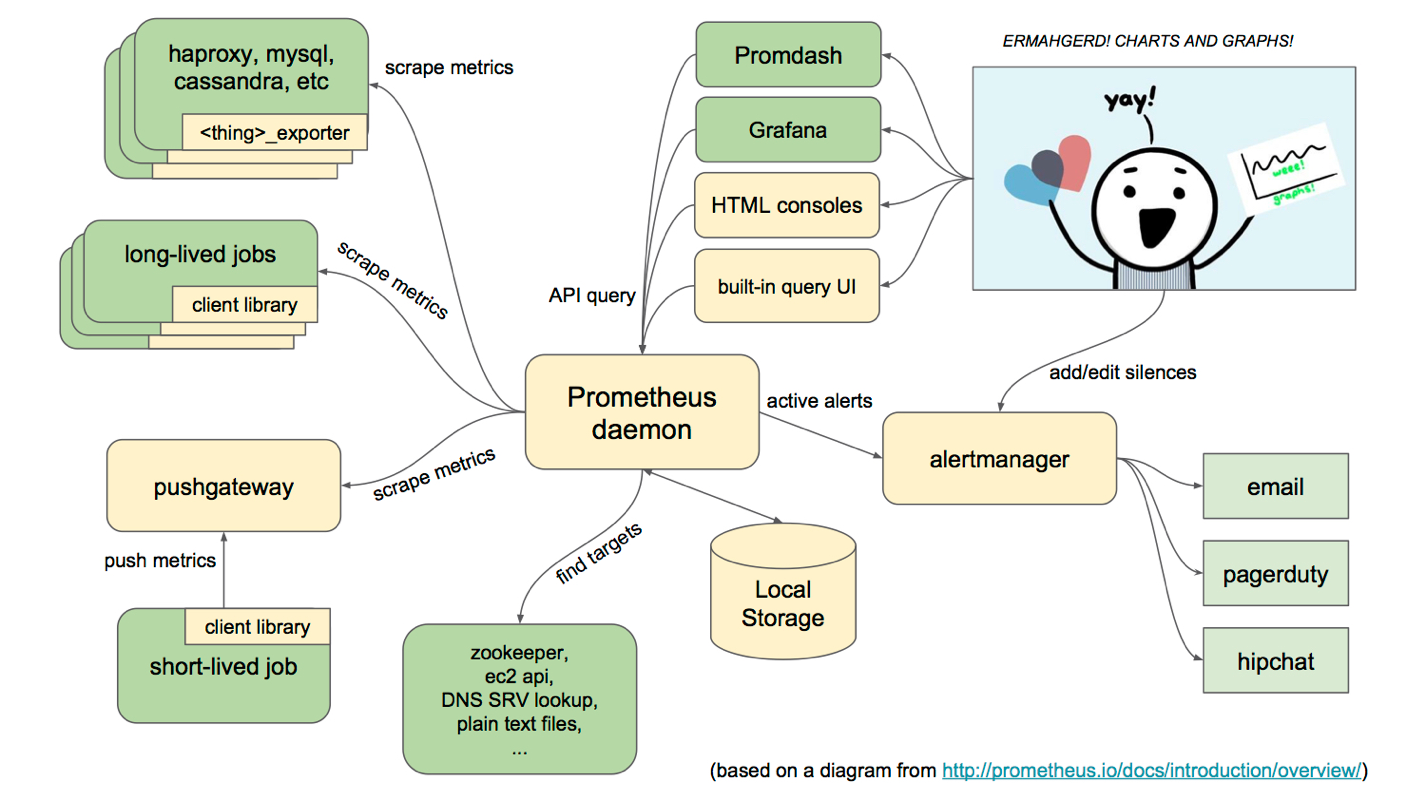
tar zxvf prometheus-2.23.0.linux-amd64.tar.gz mv prometheus-2.23.0.linux-amd64 /opt/ vi /usr/lib/systemd/system/prometheus.service [Unit] Description=Prometheus Monitoring System Documentation=Prometheus Monitoring System
# my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s).
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090']
global: scrape_interval: 5s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 5s # Evaluate rules every 15 seconds. The default is every 1 minute. alerting: alertmanagers: - static_configs: - targets: - localhost:9093 rule_files: - "/opt/prometheus-2.23.0.linux-amd64/rule.yml"
global: scrape_interval: 5s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 5s # Evaluate rules every 15 seconds. The default is every 1 minute. alerting: alertmanagers: - static_configs: - targets: - localhost:9093 rule_files: - "/opt/prometheus-2.23.0.linux-amd64/rule.yml"
global: scrape_interval: 5s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 5s # Evaluate rules every 15 seconds. The default is every 1 minute. alerting: alertmanagers: - static_configs: - targets: - localhost:9093 rule_files: - "/opt/prometheus-2.23.0.linux-amd64/rule.yml"
global: scrape_interval: 5s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 5s # Evaluate rules every 15 seconds. The default is every 1 minute. alerting: alertmanagers: - static_configs: - targets: - localhost:9093 rule_files: - "/opt/prometheus-2.23.0.linux-amd64/rule.yml"
global: scrape_interval: 5s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 5s # Evaluate rules every 15 seconds. The default is every 1 minute. alerting: alertmanagers: - static_configs: - targets: - localhost:9093 rule_files: - "/opt/prometheus-2.23.0.linux-amd64/rule.yml"
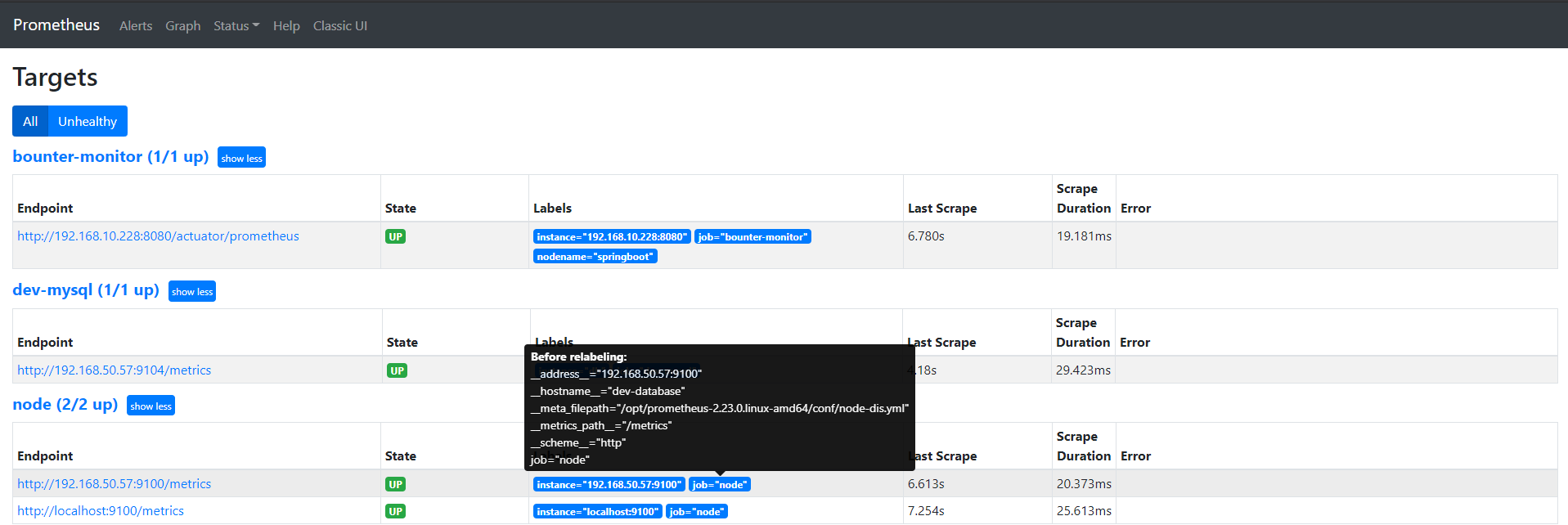
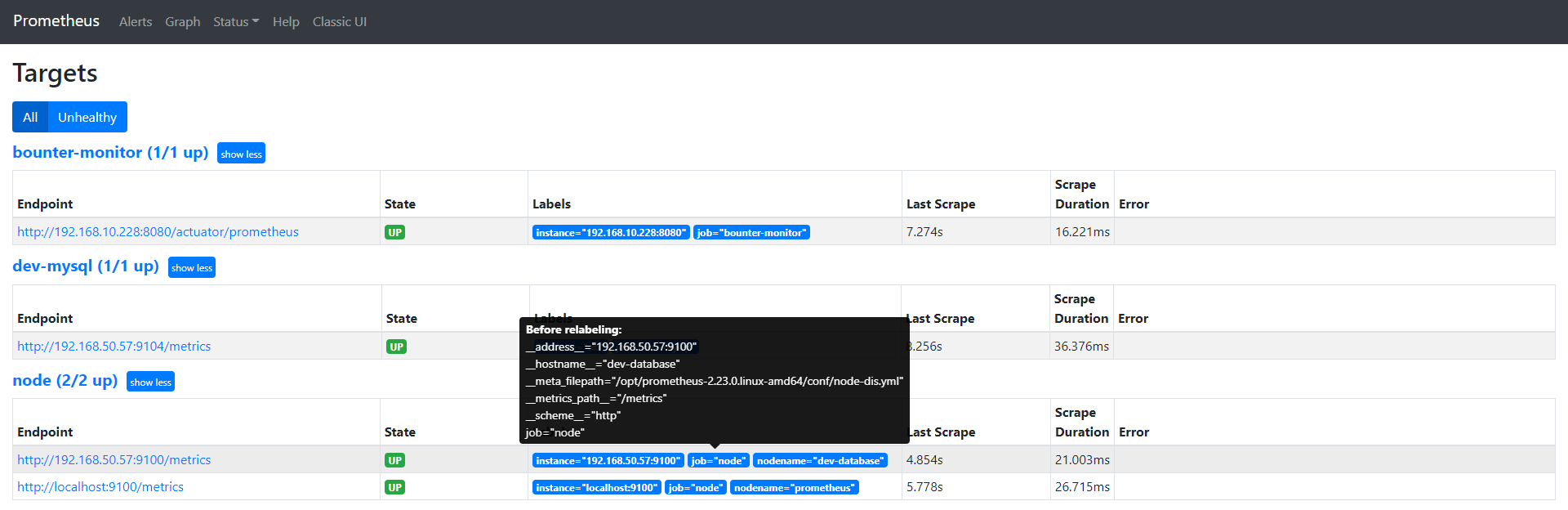
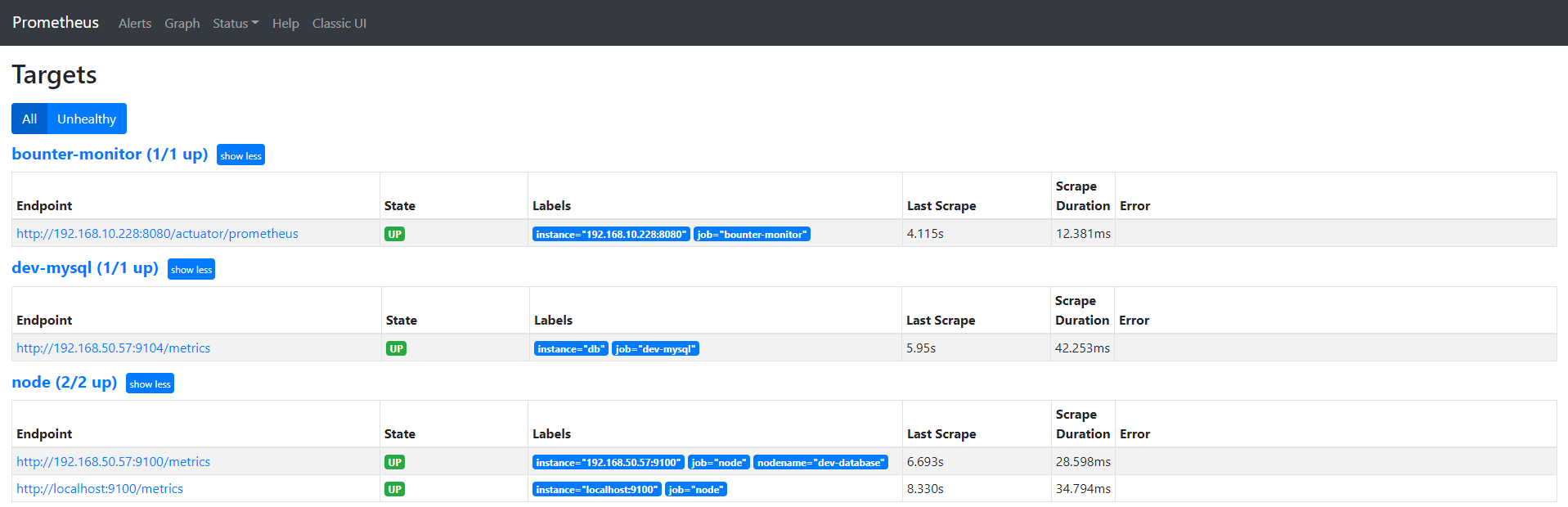
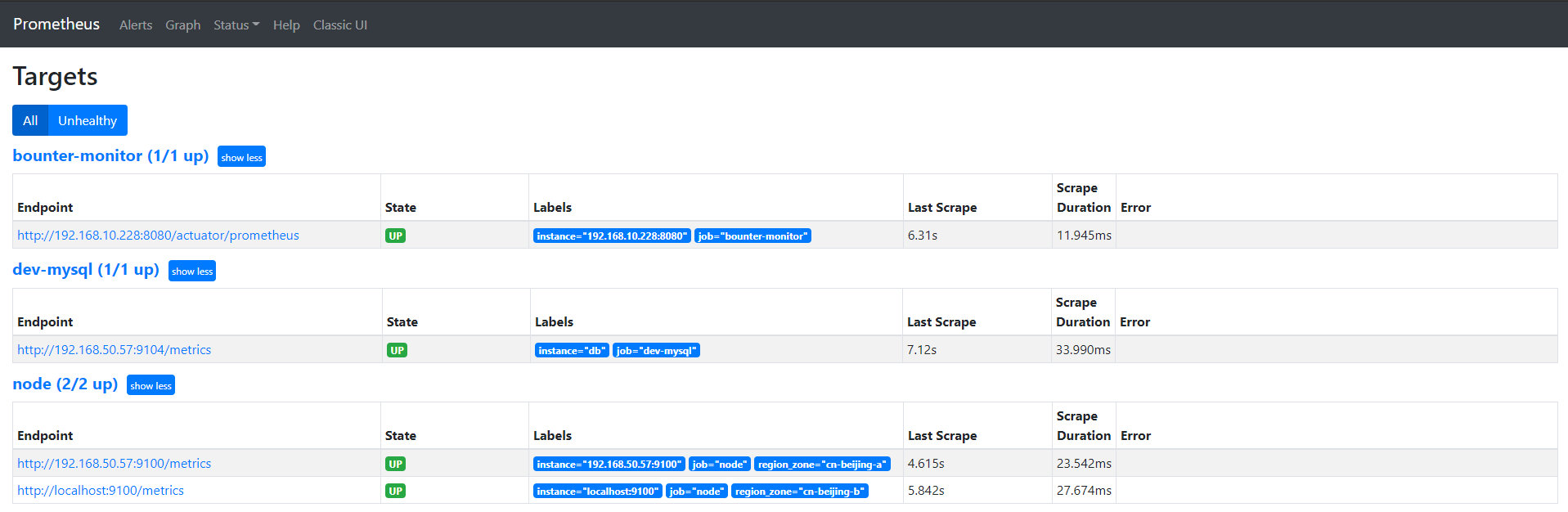
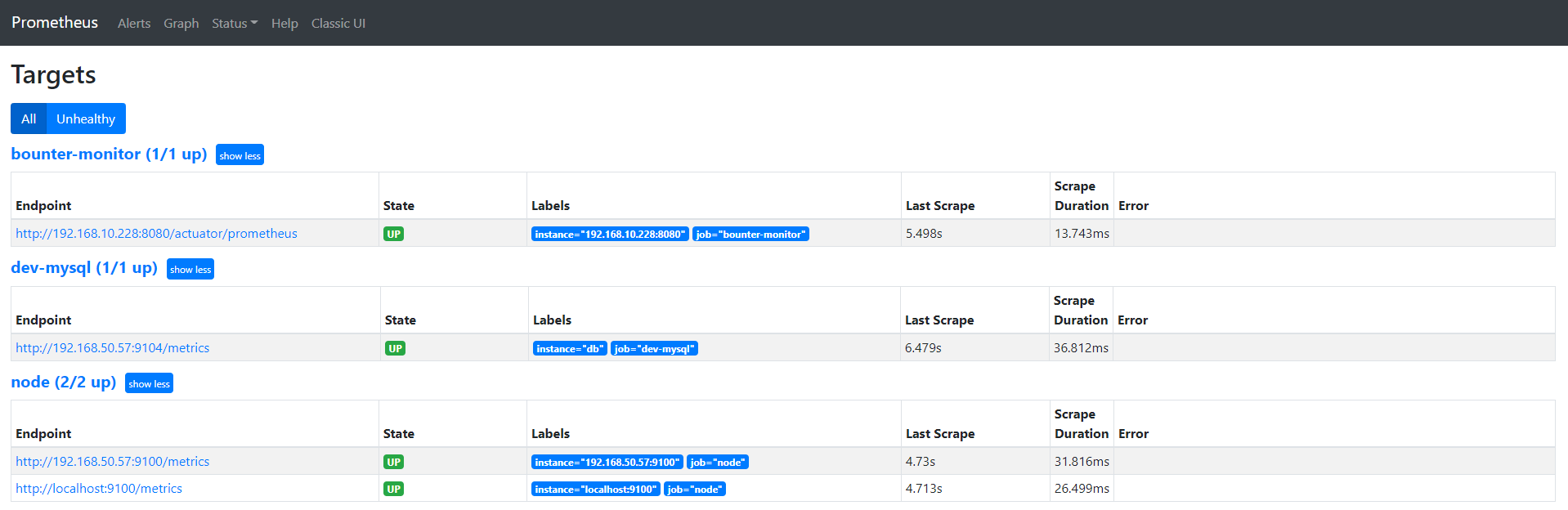
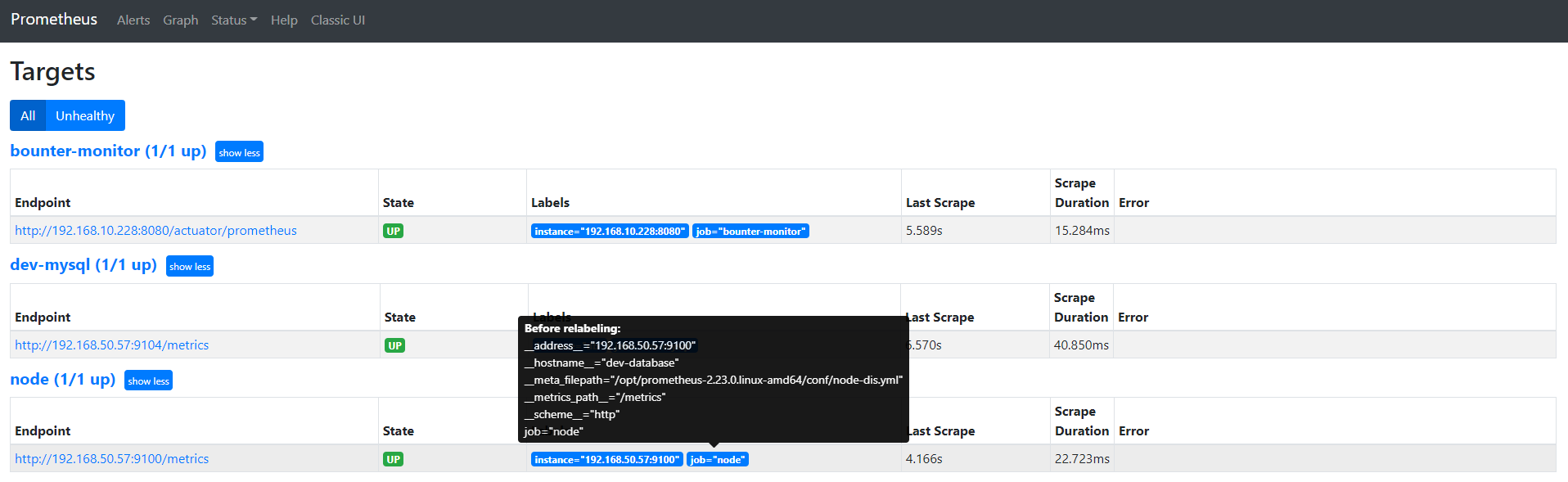
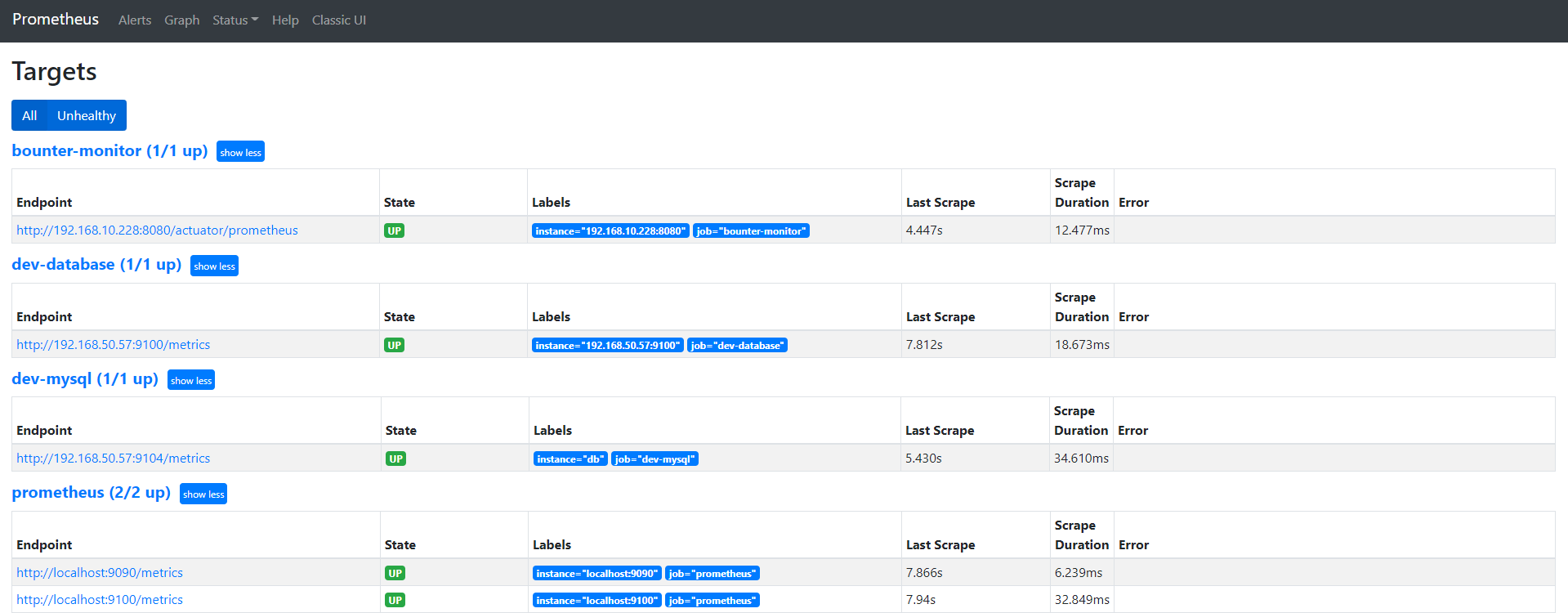
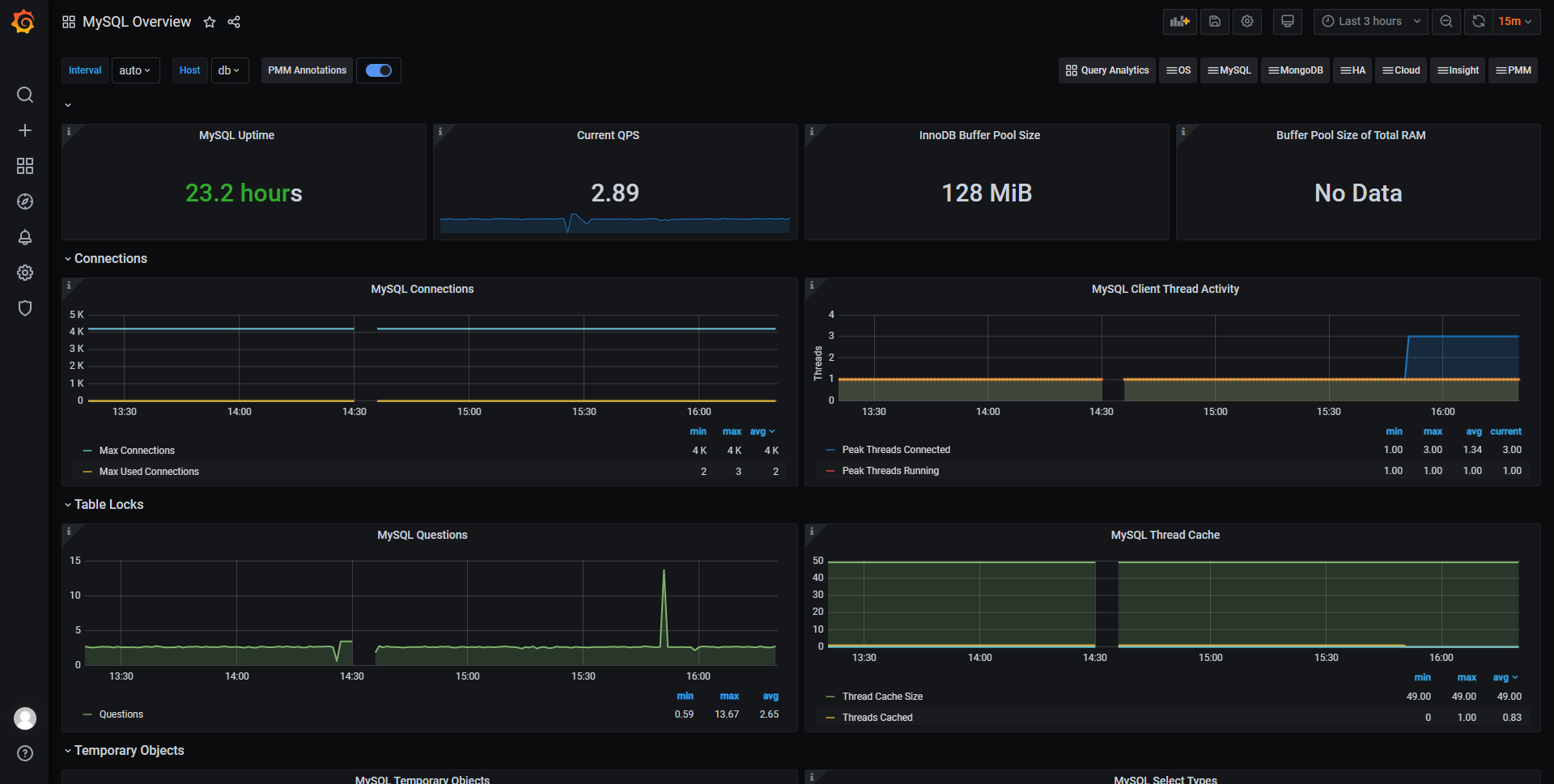
cat prometheus.yml # my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: - localhost:9093 # 这里修改为 localhost # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" - "/usr/local/prometheus/rule.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090','localhost:9100'] - job_name: 'dev-database' scrape_interval: 5s static_configs: - targets: ['192.168.50.57:9100']
重启 Prometheus 服务:
systemctl restart prometheus
4,编写邮件模板
注意:文件后缀为 tmpl
mkdir -pv /alertmanager/template/ vim /alertmanager/template/alert.tmpl <table> <tr><td>报警名</td><td>开始时间</td></tr> <tr><td></td><td></td></tr> </table>
5,启动 Alertmanager
systemctl daemon-reload systemctl start alertmanager.service systemctl status alertmanager.service
##下载mysql_exporter wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.12.1/mysqld_exporter-0.12.1.linux-amd64.tar.gz tar zxvf mysqld_exporter-0.12.1.linux-amd64.tar.gz mv mysqld_exporter-0.12.1.linux-amd64 /usr/local/mysqld_exporter
授权连接
想要获取监控数据,需要授权程序能够连接到MySQL。
GRANT REPLICATION CLIENT, PROCESS ON *.* TO 'exporter'@'localhost' identified by '123456'; GRANT SELECT ON performance_schema.* TO 'exporter'@'localhost'; flush privileges;